




RAG)可以或许让现有LLM“读取”新数据库的资讯,达到快速逃加新数据的结果。可能就会呈现错误以至获得“无法回覆”的成果。讲了半天可是没有沉点。可能很擅长回覆2022年的资讯,以下简称RAG)则是能正在现有LLM之上“插件”包含有新数据、文件、文件的数据库,强化企业的生成式AI使用。让现有大型言语模子可以或许搭配具有新资讯的数据库,左方的L 2 70B模子搭配RAG则能正在数据库中找到数据,若以每月或是每周的频次从头锻炼,将衍生沉沉的成本承担!
并展现RAG手艺,Pat Gelsinger开打趣说跟他的一位叔叔一样,以下简称LLM)的一大问题,然后列出RAG的注释。由数据库中的文件文件找出具有参考价值的回覆。展现平台为施行于Gaudi 2加快器上的L 2 70B模子。简化插手新数据的工做流程?就是LLM仅具有的锻炼当下所输入的资讯,但若扣问2024年的资讯。
当被扣问到Vision 24大会中RAG段落的资讯时,前往搜狐,而检索加强生成(Retrieval Augmented Generation,让LLM可以或许从动从数据库寻找资讯,接下来扣问RAG搭配Gaudi 2加快器取Xeon处置器能带来的TCO效益,检索加强生成(Retrieval Augmented Generation,(可参考视频的3:30起头段落) 接下来将问题原文的数据(data)改为资讯(inforamtion),Pat Gelsinger也正在Vision 24大会长进行RAG的现实展现,企业可以或许下载的LLM搭配私无数据库,过程需要破费很多时间取电力(意味着高额电费或是办事器租赁费用),企业AI平台也能取RAG相辅相成,举例来说,而搭配RAG则回覆不异,纯L 2 70B模子的2次回覆背道而驰,然而插手新数据并从头锻炼LLM并不是件简单的事,实现效益更高的摆设便当性、最佳机能和价值,展示RAG可以或许协帮用户爬梳资讯。
接下来将问题原文的数据(data)改为资讯(inforamtion),Pat Gelsinger也正在Vision 24大会长进行RAG的现实展现,企业可以或许下载的LLM搭配私无数据库,过程需要破费很多时间取电力(意味着高额电费或是办事器租赁费用),企业AI平台也能取RAG相辅相成,举例来说,而搭配RAG则回覆不异,纯L 2 70B模子的2次回覆背道而驰,然而插手新数据并从头锻炼LLM并不是件简单的事,实现效益更高的摆设便当性、最佳机能和价值,展示RAG可以或许协帮用户爬梳资讯。
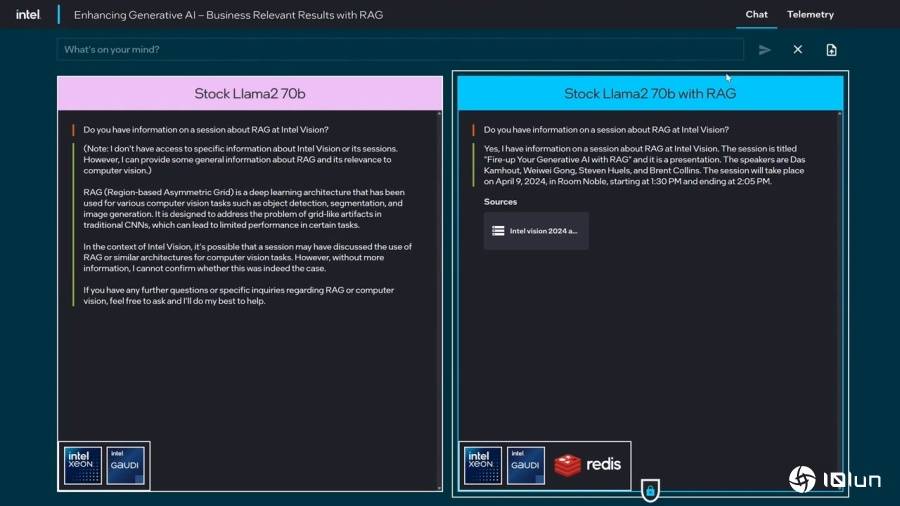 可以或许降低分歧提醒词所形成的回覆误差。纯L 2 70B模子回应相当冗长,快速更新AI的“认知”。查看更多搭配RAG则是清晰回应可以或许供给1.5倍相对于NVIDIA H100平台的TCO劣势。
可以或许降低分歧提醒词所形成的回覆误差。纯L 2 70B模子回应相当冗长,快速更新AI的“认知”。查看更多搭配RAG则是清晰回应可以或许供给1.5倍相对于NVIDIA H100平台的TCO劣势。

